Bye bye, OpenAI

When I implemented the first AI-powered features in Herodesk almost two years ago, I chose the same approach as many other developers:
Install the OpenAI SDK and use their GPT models to "do AI" in Herodesk.
Quick context: OpenAI is the company that makes ChatGPT. The "AI engine" that powers ChatGPT can also be accessed programmatically using their API, which is wrapped in a "software development kit" (SDK)... That's how you "bring ChatGPT into your own application".
It's a very easy way to get started that works out of the box.
Much like ChatGPT, I write a command, provide the necessary context, and send it to OpenAI in a single request for processing, then wait a few seconds to get the answer back.
You pay as you go – per "token" (one token is approx. 4 letters), and the price seems reasonable... Somewhere between $0.75 and $5 per million input tokens (the stuff we send to OpenAI) and between $5 and $30 per million output tokens (the reply they send back).
(The prices are publicly available at https://openai.com/api/pricing/ and vary over time and depending on which GPT model you use. Different models are good for different things, and newer models tend to be more "clever"/know more).
For the first year or so, we used AI for utility tasks such as translation, classification, spam detection, and text manipulation, etc.
Then, on October 2nd 2025, we launched our AI agents: Autonomous agents that can understand and reply to customer questions on chat, e-mail and social media, that know all about your business and products and that can automatically find order- and customer details and even create, modify or cancel orders on behalf of the customer. Online 24/7 and doing all of this without ever involving a human!
This significantly increased both the complexity and amount of "AI work" we do.
Whereas the utility tasks are fairly simple (one command: translate text, send input, receive output), the AI agents are magnitudes more complex.
To answer a single question from a customer, the agent must:
- Classify the question (what is the customer asking about)
- Find the right tools to answer the customer
- Look up relevant data in the database to have the necessary knowledge about the question (and maybe repeat this step multiple times to search across different data sources)
- Execute necessary actions (fx find a track and trace number for a specific order or change a delivery address)
- Compose an answer based on the found data
- Verify that the answer is correct and does not violate any rules, constraints, og guardrails
- Rewrite the answer based on the user's communication guidelines
7+ steps to write a single reply.
All the infrastructure and logic for these steps are things we build ourselves. We "just" use AI to analyse, make decisions and compose answers
This is all fine and well. It works great, and we are seeing good results from OpenAI's GPT models.
But as things grew- we got more customers, and everything developed- I started seeing three challenges...
1) The cost of using OpenAI.Check out this graph:
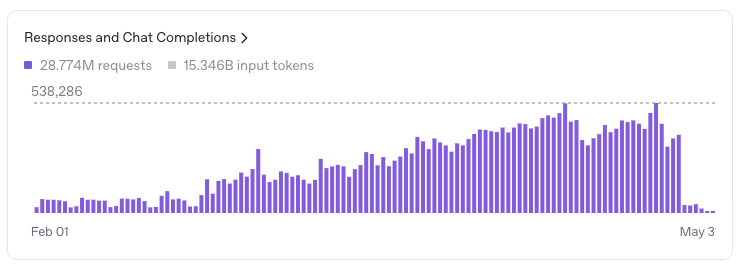
It shows the number of requests and amount of input tokens we've sent to OpenAI since February 1st this year. Almost 29 million requests using more than 15 billion tokens.
And the usage is only increasing, and doing so fast. More customers, more usage, more (complex) requests and AI agent usage.
The cost was getting out of control.
This isn't just a Herodesk thing. It's a big theme in Tech right now: "the cost of AI" is running amok in many businesses, eating away at margins at an uncontrollable pace.
Obviously, I don't want that!
2) GDPR, baby. GDPR!
Over the past months, we've started to get a new type of customer. Businesses that care A LOT about GDPR (for various reasons, but they do, nevertheless).
Even though we've ensured that OpenAI never uses the data we send to train its model, we've ensured that it's always "fire and forget", that all data is anonymised and that all the knowledge that the AI agents are trained on is hosted in our own data centre in Germany, that's not enough.
If OpenAI is listed as a sub-data processor, you're out!
Which opens a huge opportunity for us. If we can deliver the AI services without using OpenAI (or Anthropic or one of the other "big ones"), we have a unique selling point that none of our competitors can or want to offer.
3) I really don't like using OpenAI (or any other "big provider" like that)
It's the same reason I chose to host Herodesk on a bunch of clean Ubuntu servers with Hetzner in Germany, instead of using AWS, GCP, Azure or one of the other "cloud platforms".
I like it self-hosted. It's cheaper. More flexible. No vendor lock-in. Fully GDPR compliant, etc...
So the fact that we've been using OpenAI has honestly annoyed me for some time. I'd much rather do it myself.
Which brings me back to where this blog post started: Bye-bye, OpenAI.
The solution to all three problems has become (significantly more) available this year: Self-hosted open-source LLMs.
Instead of sending our "AI work" to OpenAI, we send it to our own servers.Instead of using OpenAI's GPT models (the "brains", remember), our own servers are installed with open-source alternatives.
And the best part? There are "wrappers" that make all of this available via APIs with the same specifications as OpenAI's, meaning it's a drop-in replacement from the Herodesk application's point of view.
There are a few reasons, however, as to why everyone doesn't "just do this".
For starters, it requires some huge GPUs to compute the AI work. These are insanely expensive (+10k USD and up each). And each operation is computationally expensive, so you need quite a lot of them.
Then comes the setup and configuration. With thousands of open-source models available, you gotta find the right one and configure it exactly to your use case. Whereas OpenAI has huuuuuuge models that are general purpose, it's not possible for me to run the same kinds of models (that would require hardware costing hundreds of thousands of dollars), so I gotta find and configure the right one for our specific use case.
And finally the technical setup. Instead of just calling the OpenAI API endpoint, you have to build the whole infrastructure yourself.
Fortunately, that's the kind of work I like doing, and when we can save some money (help us keep the price of Herodesk low) and host everything in Denmark/Germany (so it's 100% GDPR compliant), it's win-win-win.
Here's the breakdown of our new AI setup.
As we don't have our own physical servers but rent virtual servers with Hetzner, buying the physical GPUs and putting them in a data centre isn't an option.
- Instead, we've rented NVIDIA RTX PRO 6000 Blackwell GPUs from Scannet in Denmark. My old workplace. They offer a surprisingly competitive price.
- The GPUs are connected to virtual Ubuntu servers (some with one GPU each and others with two GPUs - I'll get back to this).
- A simple WireGuard tunnel connects these "AI servers" in Denmark to the rest of our internal setup in Germany, so our Herodesk application can access them without exposing it to anyone else (security, and all that)
As I said, we cannot just have "one general-purpose model" like OpenAI that works for everything. We need different models for different purposes.
For the simpler things like translations, classification, etc., we use the Qwen3.5-27B model (the "27B" means it has 27 billion parameters. You can compare this to neural paths in your brain. More parameters = neural paths = more knowledge = smarter model). This works fine on one RTX 6000 GPU. Because of the amount of work, I have two servers with this setup and load-balance between them.
The AI Agents are more complex and need more sophisticated models. For them, I use the Qwen3.5-122B-A10B. This has 122 billion parameters, meaning it is way smarter. But also bigger. So it cannot "fit" in a single GPU. It needs to be split among two to have enough memory and GPU power to work.
All our AI workers use vLLM, which provides an OpenAI-compatible interface (a drop-in replacement).
As for scalability, it's fairly easy as well. Instead of paying per token with OpenAI, I simply order more GPU power from Scannet when we need it. Delivery is within a few hours.That is a "bump" in cost (you do the math; when it costs more than $10k to buy one GPU in retail, they aren't exactly cheap to rent, but Scannet does a great job here!), but also a big increase in capacity.
This is now live! And as you can see from the graph in the first image, our OpenAI usage drops to near-zero on May 26th when we made the switch.
Significant cost savings.
Fully GDPR compliant and self-hosted.
Our customers don't notice the change at all.
And a fun and interesting project :-)
Win-win-win!