You cannot trust your AI

You cannot trust AI.
That's not a hot take. That's an engineering constraint, and it's the thing most companies building AI products right now are quietly hoping you won't think too hard about.
The demos are slick. The benchmarks are impressive. But here's what most of them won't tell you: LLMs are non-deterministic. Ask the same question ten times and you get ten different answers. You cannot make them fully deterministic. You cannot guarantee they won't hallucinate. You can constrain the problem, reduce the probability, and build hard rails around the output. But "trust" in the way you'd trust a database query? That doesn't exist.
This matters a little when AI is answering questions about return policies. It matters enormously when it has access to customer data.We've been building AI agents into Herodesk for a while now. The pitch is genuinely compelling: instead of a webshop owner's support team manually answering "where is my order?" for the 40th time that week, the agent handles it. Instantly. Correctly. For around €0.30 per resolved conversation (our price, anyway). Good deal for everyone.
But making it work safely is a completely different problem than making it work at all.
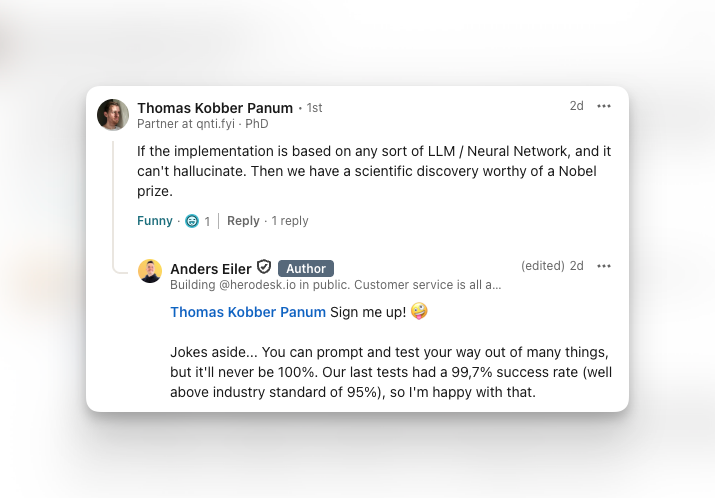
The first challenge is containment. An AI agent has to work only with what it's been given. Not the open internet. Not its general training knowledge. Not some hallucinated version of your store's return policy. Just the data you've explicitly provided: your website content, product feed, FAQ articles, help centre docs. We enforce this through system prompting and our own testing suite. We're currently running against GPT 5.4, and our automated test pass rate sits at 99.8%, well above the 95% industry benchmark. The remaining 0.2% are what we call "flaky" answers, where the model oscillates on a true/false question rather than committing. That number gets smaller as the models improve. It (probably?) never reaches zero, though.
That's fine for general questions. The hard part is order data.
A few weeks ago, an AI support provider screwed up badly. I won't name them, it's not important for this, but you can probably find it if you look. A tester asked their AI agent for order details by typing in a random order number. No verification, no friction, nothing. The agent, doing its absolute best to be helpful, returned everything: full name, home address, complete order contents, for a completely different customer.
Holy shit.
Some random person on the internet asked a chatbot for an order number and got handed someone else's personal data on a silver platter. By a company actively selling this product to webshops. They claim they fixed it, and maybe they did, but the trust is gone, the data is already out, and they're playing GDPR roulette with fines that can hit 4% of global annual turnover.
This isn't a one-off horror story. It's what happens when you treat a prompting problem as a security architecture. An LLM that has access to order data and a system prompt that says "don't share data with the wrong people" is not a security architecture. The model doesn't understand data ownership, it understands patterns in text. Telling it to be careful is not the same as making it structurally incapable of leaking.
The reason this happens is that someone shipped a product demo as a product.
At Herodesk, we have over 50,000 lines of code written specifically for AI agent management, separate from the rest of the product. That number exists because we don't treat this as a prompting problem. The core principle is simple: the AI never has access to customer data it hasn't been explicitly given for this specific conversation, after identity verification.
When a customer asks about an order, we verify their identity first. Verified or not, binary. If not, the conversation stops. If yes, we use our webshop integrations (the ones we also built ourselves) to fetch only that customer's orders and inject only that data as context for the AI's response. The AI doesn't have a connection to your order database. It can't look up other customers. It receives exactly the data it needs, generates a response, and that's it. Same logic applies for track and trace, address changes, cancellations, returns. Every action that touches sensitive data goes through this verification and scoping layer before the AI ever sees it.
It sounds straightforward. It isn't. But it's what makes it possible to actually trust the output.
Here's the part that's actually your problem, though. When you add an AI agent to your customer support, you are not outsourcing your data responsibility. You are extending your data infrastructure to a third-party system. If that system leaks your customers' data, the GDPR liability doesn't land on the AI provider alone. It lands on you, too, because you are the data controller.
Most webshop owners I've talked to haven't thought about this at all. They see a clean UI, a smooth demo, a reasonable per-conversation price, and they sign up. They don't ask how identity verification works. They don't ask where order data goes. They don't ask what the test pass rate on hallucination prevention is.
The AI support market is moving fast and a lot of the products in it were built by people who are much better at growth than at data security. Again, not an accusation, merely an observation of a pattern. The pressure to ship and capture a fast-moving market creates real incentives to cut corners on the parts users can't see, and data security is exactly the kind of thing that gets cut. But this is not the place to do that.
So before you add any AI agent that touches customer order data, ask your provider how identity verification works. Ask what happens if someone queries an order number that isn't theirs. Ask for the actual architecture, not the marketing page.
If they can't answer clearly, that's your answer.